Uusi tutkimus: Suomalainen uutismedia ja generatiivisen tekoälyn tiedonlouhinta


Harvat ChatGPT:n käyttäjät oikeasti tietävät (tai edes välittävät) mihin tietoon työkalun vastaukset perustuvat.
Yksi merkittävä lähtökohta tekoälyn koulutuksessa on verkkosivustojen tiedonlouhinta, eli verkkosivustojen sisältojen automaattinen analysointi.
Käydään läpi erityisesti tiedonlouhinta tekoälyn koulutuksessa ja erityisesti miten uutismediat Suomessa ovat alkaneet estämään tekoälyn koulutuksen sisällöllään.
Kuinka tiedonlouhinta liittyy generatiiviseen tekoälyyn
Monet generatiivisen tekoälyn ratkaisut, kuten ChatGPT, perustuvat suuriin kielimalleihin. Nämä kielimallit keräävät paljon ihmisten luomaa sisältöä ja tulkitsevat, missä yhteydessä sanoja ja tietoa on käytetty kouluttaakseen generatiivisen tekoälyn algoritmejä.
Generoinnin prosessissa harva tietää, mihin tietolähteeseen vastaus perustuu. Tekoäly yksinkertaisesti luo parhaan arvion siitä, missä yhteydessä eri sanat liittyvät toisiinsa ja pyrkii vastaamaan käyttäjien kysymyksiin kehittyneen koulutusdatan mukaan.
Vaikka generatiivisen tekoälyn kehittäjät eivät anna tarkkaa kuvaa koulutusdatansa tietolähteistä, tiedetään, että monet hyödyntävät verkkosivustojen tietojenlouhintaa ja hakurobotteja.
Hakurobottien käyttöä ei voi estää, mutta sitä voi rajoittaa. Verkkosivustojen omistajat voivat estää hakurobottien pääsyn sisältöön yksinkertaisesti lisäämällä "Disallow"-koodin verkkosivustonsa lähdekoodiin. Haasteena tässä käytännössä on, että jokainen hakurobotti on estettävä erikseen. ChatGPT:tä hyödyntävien GPTBot- ja ChatGPT-user-robottien lisäksi on olemassa useita muita samankaltaisia tekoälyä kouluttavia hakurobotteja. Verkkosivuston ylläpitäjän tulisi olla hyvin tietoinen siitä, mitä roboteja käy heidän sivuillaan.
Kysymys kuuluukin, miten suomalaiset sanomalehdet ja uutismediat ovat pyrkineet estämään generatiivisen tekoälyn tiedonlouhintaa?
Kuinka suomalaiset uutismediat estävät tekoälyn hakubotteja helmikuussa 2024
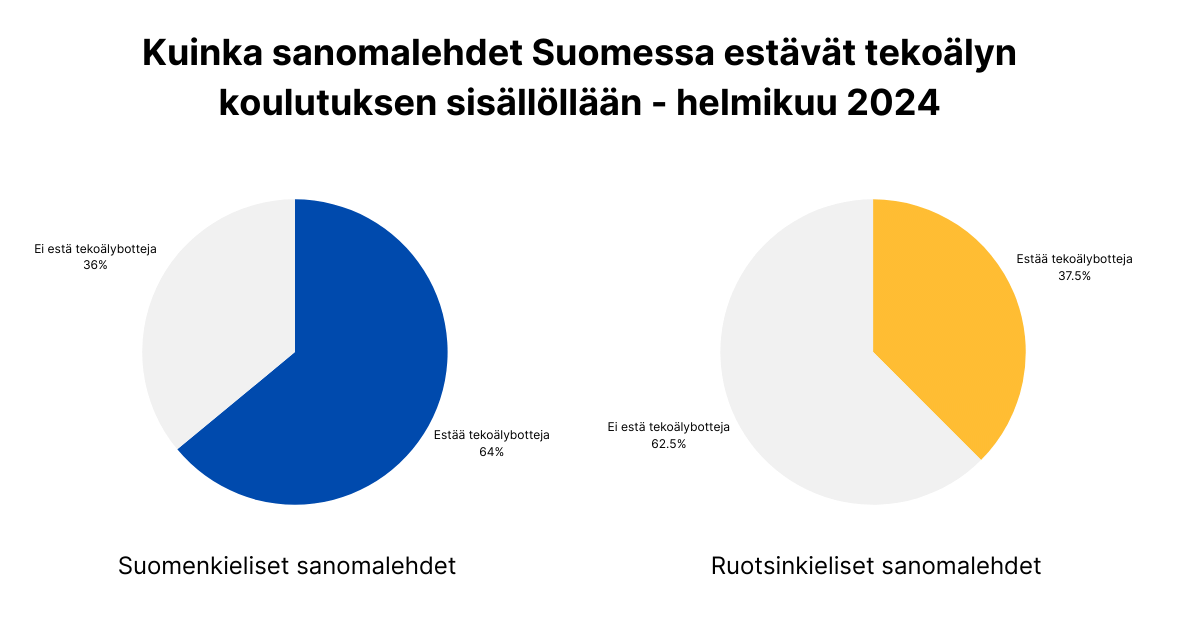
Tutkimuksemme osoitti, että jo 64% verkkossa ilmestyvistä sanomalehdistä Somessa estää tekoälyä kouluttavat hakubotit.
Lisäksi huomasimme, että:
- Ruotsinkieliset uutismediat estävät tekoälyä kouluttavia hakubotteja selvästi vähemmän kuin suomenkieliset sivustot, löysimme estoja vain 37,5% Suomen ruotsinkielisistä uutissivustoista ja sanomalehtien verkkosivuista.
- Yle ei toistaiseksi näytä antavan ohjeistusta ollenkaan tekoälyä hyödyntäville hakuboteille yle.fi -sivustolla.
- Suurista mediakonserneista Keskisuomalainen ja Sanoma estävät eniten erilaisten bottien päästyä sisältöönsä.
- 35% uutismediasivustoista Suomessa estää myös Facebookin ja Amazonin käyttämät tekoälyä kouluttavat hakubotit.
- CCBot, Google-Extended, GPTBot ja ChatGPT-user ovat Suomessa useimmiten estetyt tekoälyn koulutuksessa käytettävät botit.
- Kokonaisuudessa 58% kaikista suomalaisista uutismediapalveluista estää jonkun generatiivista tekoälyä kouluttavan hakubotin pääsyn verkkosivuston sisältöönsä.
Lisätietoa tutkimuksesta
Tutkimuksen suoritti 8-9 helmikuuta tämän artikkelin kirjoittaja, markkinointikonsultti Lari Numminen. Tutkimuksen tarkoituksena oli selvittää, kuinka 100 suomalaista sanomalehteä ja muuta uutismediapalvelua estää tekoälyä kouluttavia hakubotteja verkkosivustojensa robots.txt-tietokannassa.
Metodologia:
Käytännössä analysoin huolellisesti tunnetuimpien suomalaisten sanomalehtien ja uutismediapalveluiden verkkosivustojen robots.txt-tiedostot. Merkitsin ylös, miten eri hakubotteja, joita käytetään tekoälyn kouluttamisessa, oli estetty "Disallow"-merkinnällä. Huomioon otettiin ainoastaan hakubotit, joiden tiedettiin vaikuttavan suurten kielimallien koulutukseen. Esimerkiksi Googlebotin tai muiden tunnettujen indeksointirobottien käyttöä ei laskettu, ellei niillä ollut suoraa yhteyttä tekoälyn koulutukseen.
Määritelmät:
- Sanomalehti: Verkkosivusto, joka julkaisee säännöllisesti maanlaajuisia tai paikallisia uutisaineistoja.
- Muu uutismedia: Merkittävä uutismedialähde, jolla on runsaasti uutisia ja kirjoitettua sisältöä verkkosivustojen kautta luettavissa.
- Yhtymä: Mediapalvelun omistaja tai julkaisija. Tutkimuksessa havaittiin merkittäviä eroja siinä, miten eri mediayhtymät suhtautuvat generatiivisen tekoälyn estämiseen.
- Kieli: Uutismedian pääasiallinen julkaisukieli, joko suomi tai ruotsi.
Tutkimuksen ulkopuolelle jäivät pääosin käyttäjien julkaisemat sisällöt sisältävät sivustot (esim. vauva.fi, suomi24.fi) sekä ne uutismediat, joiden sisältöä ei voitu helposti lukea kirjautumatta verkkosivustojen kautta.
Mahdolliset kysymykset tai korjaukset tilastotietoihin voi lähettää osoitteeseen lari@generatemore.ai.


