Mitä on syväoppiminen?


Syväoppiminen tekoälyn osa-alue, joka keskittyy opettaamaan tietokoneita käsittelemään tietoa tavalla, joka matkii ihmisten ajattelua. Syväopin mallit voivat esimerkiksi tunnistaa monimutkaisia kuvioita kuvista, tekstistä, äänistä ja muista tiedoista tuottaen ihmismäisen tarkkoja oivalluksia ja ennusteita.
Syväoppimisen määritelmä
Syväoppiminen on koneoppimisen alalaji, joka perustuu tekoälyjen ja algoritmien käyttämiseen monimutkaisten tehtävien, kuten kuvantunnistuksen, luonnollisen kielen käsittelyn ja äänentunnistuksen suorittamiseksi. Tämän tekniikan avulla koneet voivat luoda monimutkaisia malleja suurista tietomääristä.
Syväoppimisen juuret juontuvat 1950-luvulle, kun ensimmäisiä neuroverkkoja alettiin kehittää. Viime vuosikymmeninä, erityisesti laskentatehon ja suurten tietomäärien ansiosta, syväoppiminen on saanut merkittävän roolin koneoppimisen alalla.
Syväoppimisen perusperiaatteet
Syväoppiminen perustuu usein monikerroksisiin neuroverkkoihin. Jokainen neuroverkon kerros käsittelee tietoa edellisestä kerroksesta ja välittää sen seuraavalle. Koulutusvaiheessa verkon painot mukautuvat oppimaan tietomallista.
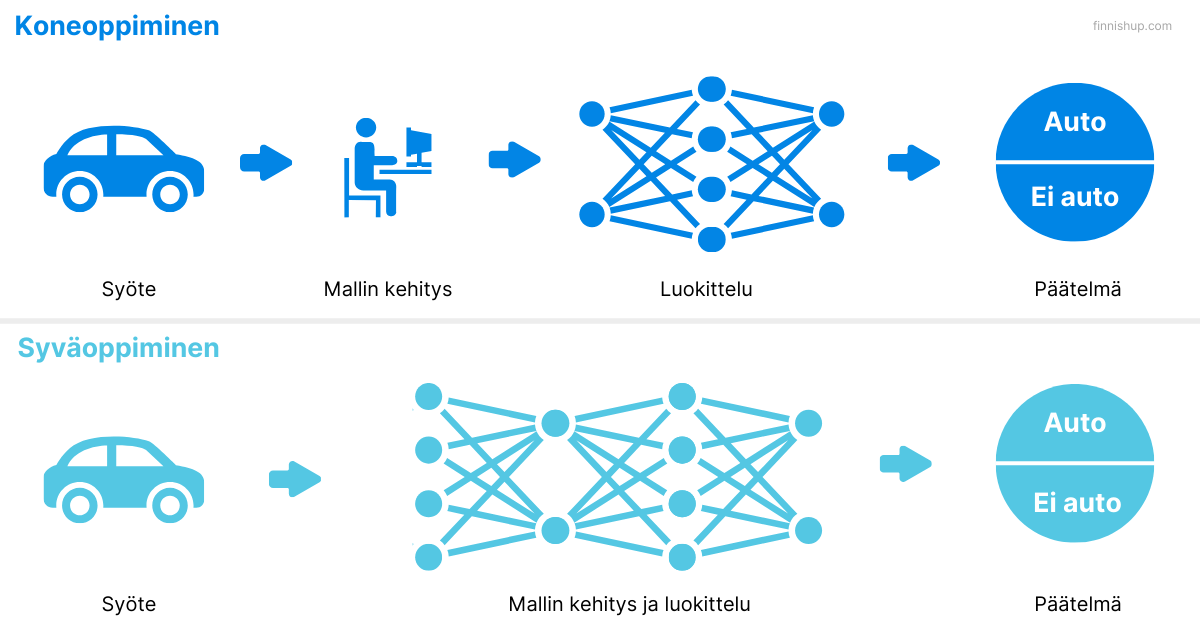
Toisin kuin perinteinen koneoppiminen, joka vaatii manuaalista piirteiden erottelua, syväoppiminen pystyy itse erottamaan tarvittavat piirteet suoraan raakadatan perusteella.
Syväoppimisverkon komponentit
Syväoppimisverkko koostuu useista peruselementeistä, jotka yhdessä mahdollistavat syvällisen oppimisen:
- Neuronit: Keinotekoiset neuronit ovat perusyksiköitä, jotka jäljittelevät ihmisen aivojen neuroneja.
- Painot ja vinokulmat: Nämä ovat parametreja, joita säädellään oppimisprosessin aikana ja jotka määrittävät neuronin aktivoinnin vahvuuden.
- Aktivointifunktiot: Nämä funktiot auttavat päättämään, aktivoituuko neuron vai ei.
- Syöttö- ja piilokerrokset: Syväoppimisverkko koostuu yleensä monista kerroksista, joihin kuuluvat syöttökerros ja useita piilokerroksia, jotka mahdollistavat monimutkaisten piirteiden oppimisen.
- Virheenkorjaus ja takaisinpropagointi: Nämä mekanismit ovat vastuussa oppimisprosessin säätelystä ja virheiden korjaamisesta.
Syväoppimisen sovellukset
Syväoppimisen suosio kasvaa jatkuvasti, koska sen avulla voidaan käsitellä ja analysoida suuria tietomääriä, tunnistaa monimutkaisia kuvioita ja parantaa automaation tasoa monilla aloilla, kuten terveydenhuollossa, liikenteessä ja viihteessä, tehostaen palveluita ja ratkaisten ongelmia, joita perinteiset menetelmät eivät kykene ratkaisemaan.
Syväoppimista käytetään laajalti eri aloilla, mikä osoittaa sen monipuolisuuden ja tehokkuuden. Tässä muutamia konkreettisia esimerkkejä:
- Itseohjautuvat ajoneuvot: Syväoppimismallit käsittelevät tietoja ajoneuvojen sensoreista ja kameroista tehdäkseen reaaliaikaisia ajoa koskevia päätöksiä, mahdollistaen autonomisen ajamisen.
- Kuvantunnistus ja analyysi: Lääketieteen alalla syväoppiminen auttaa tunnistamaan ja analysoimaan röntgenkuvia ja muita skannauksia tunnistaen sairauksia, kuten syöpää, tarkemmin ja nopeammin kuin ihmisasiantuntijat.
- Puheentunnistus: Älypuhelinten virtuaaliassistentit, kuten Siri ja Google Assistant, käyttävät syväoppimista ymmärtääkseen ja prosessoimaan käyttäjän puhetta.
- Kielenkääntäminen: Konekääntäjät, kuten Google Kääntäjä, hyödyntävät syväoppimista tarjotakseen yhä tarkempia ja luonnollisempia käännöksiä.
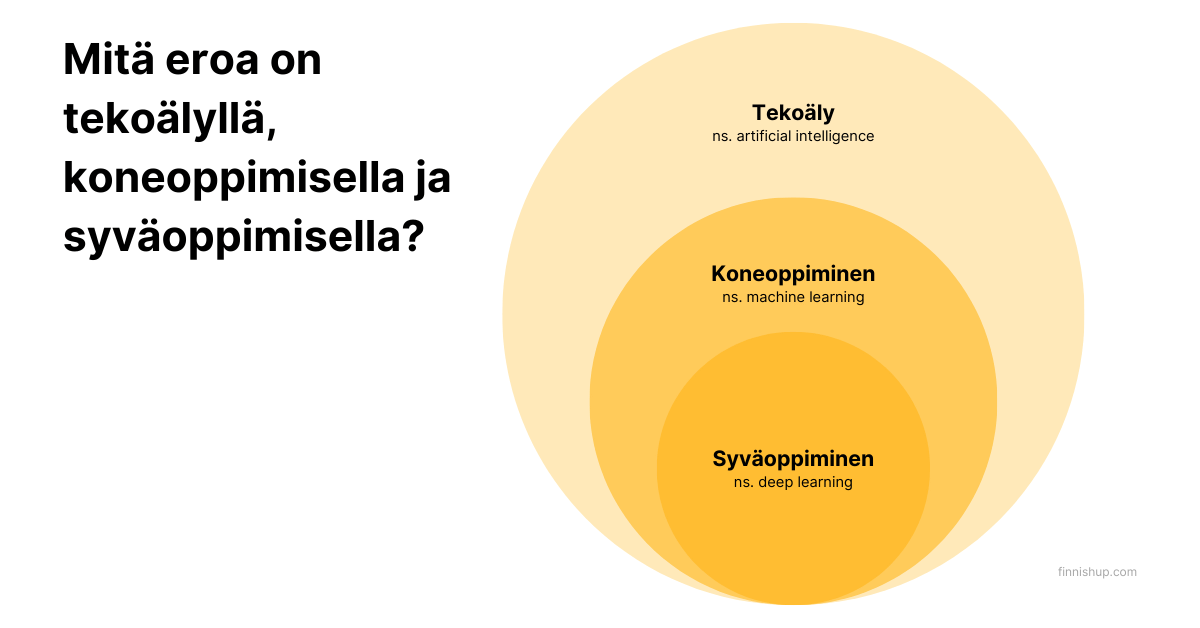
Syväoppiminen vs koneoppimisen
Koneoppiminen on laaja käsite, joka sisältää algoritmeja, jotka voivat oppia datasta ja tehdä ennusteita tai päätöksiä. Syväoppiminen on erikoistunut koneoppimisen haara, joka käyttää monikerroksisia neuroverkkoja mallintamaan monimutkaisia kuvioita suurissa datamäärissä. Koneoppimisen perinteiset algoritmit keskittyvät yleensä pintatason oppimiseen, kun taas syväoppiminen tunkeutuu syvemmälle datan rakenteeseen.
Syväoppimisen edut verrattuna koneoppimiseen:
Syväoppiminen tarjoaa useita etuja verrattuna perinteiseen koneoppimiseen:
- Kyky käsitellä suuria ja monimutkaisia datasarjoja: Syväoppiminen on tehokasta erityisesti kun data on monimuotoista ja laajaa.
- Automaattinen ominaisuuksien poiminta: Toisin kuin perinteisessä koneoppimisessa, syväoppiminen pystyy itse identifioimaan tärkeät piirteet ilman ihmisen puuttumista.
- Parannettu tunnistustarkkuus: Syväoppimismallit ovat usein tarkempia ja luotettavampia monimutkaisten kuvioitten ja suhteiden tunnistamisessa.
Syväoppimisen haasteet
Vaikka syväoppiminen on erittäin tehokas, sillä on myös haasteita. Koulutus vaatii suuria tietomääriä ja laskentatehoa. Lisäksi syväoppimisen malleja voi olla vaikea tulkita.
Vaikka syväoppiminen on voimakas työkalu, sillä on myös omat haasteensa:
- Suuri datavaatimus: Tehokkaan syväoppimismallin kouluttaminen vaatii valtavia määriä merkityksellistä dataa.
- Laskentatehon tarve: Syväoppiminen vaatii merkittävää laskentatehoa, mikä voi olla kallista ja rajoittaa sen käyttöä.
- Mustan laatikon ongelma: Syväoppimismallit voivat olla kuin mustia laatikoita, joiden sisäisiä prosesseja on vaikea tulkita.
- Yli- ja alisovittaminen: Mallit voivat oppia datan satunnaiskohinaa, mikä heikentää niiden yleistettävyyttä uusiin tietoihin.
Vaikka syväoppimisen mallit ovat kykeneviä tunnistamaan monimutkaisia kuvioita ja tuottamaan tarkkoja ennusteita, ne eivät ole erehtymättömiä. Mallin tarkkuus riippuu monista tekijöistä, kuten käytetystä datasta, mallin rakenteesta ja opetusmenetelmistä. Virheellinen tai puutteellinen opetusdata, ylisovitus tai mallin virheellinen konfigurointi voivat johtaa virheellisiin tuloksiin.
Syväoppimisen tekniikat kehittyvät jatkuvasti, ja niiden soveltamisala laajenee. Tulevaisuudessa voimme nähdä entistä tarkempia ja monimutkaisempia syväoppimismalleja, jotka pystyvät ratkaisemaan entistä monimutkaisempia ongelmia.
Summa summarum
Syväoppiminen on vallankumouksellinen tekniikka, joka on muuttanut tekoälyn maisemaa. Sen avulla olemme kyenneet saavuttamaan huomattavia edistysaskeleita monilla aloilla, ja sen merkitys kasvaa jatkuvasti tulevaisuudessa.


